
MIT 打破生成式 AI 框架:不靠生成器也能改圖、造圖
MIT 打破生成式 AI 框架:不靠生成器也能改圖、造圖

InfoAI全球AI新聞精選與解讀|MIT 發表不需生成器的影像轉換法
麻省理工學院(MIT)近期對外發表一項顛覆性的研究成果:透過一個訓練良好的 tokenizer 與 detokenizer,就能不依賴傳統的生成器,完成圖像生成、修改與重建任務。
這項研究首次在主流程中完全移除 generator 元件,僅透過直接優化一組潛在 token 的方式,即可讓一張圖「變身」為另一種物種、風格或語意目標,展現前所未有的靈活與效率。
研究成果已於 2025 年機器學習界年度頂級會議 ICML 發表,由 MIT CSAIL 團隊與 Facebook AI Research 合作主導,參與者包含 Lukas Lao Beyer、Kaiming He 與 Sertac Karaman 等知名研究者。
01|這項技術到底突破了什麼?
過去幾年,生成式 AI 工具如 DALL·E、Midjourney、Stable Diffusion 等之所以能大放異彩,核心在於:它們具備一個訓練良好的「生成器」,能夠根據使用者的提示詞將潛在空間中的語意資訊轉譯為圖像。
但這次 MIT 的研究指出,其實生成器不是必需品。
該研究提出一種名為 Token Optimization 的方法,流程如下:
使用一個事先訓練好的 Tokenizer,將原始影像壓縮為少量的一維 token(每張圖僅需 32 個 token)。
利用外部語義模型(如 CLIP)評估這些 token 對應圖像與語義目標(例如文字提示)的相符程度。
在潛在空間中直接優化這些 token,使得還原後的圖像更接近預期語意。
使用 Detokenizer 將更新後的 token 還原為圖像。
這代表什麼?我們不再需要仰賴龐大的神經網路來將 prompt 映射成圖像,而是轉向操作「壓縮後」的語意表示,從 token 層次直接控制圖像轉換。
02|核心概念拆解:為什麼不需要 generator?
傳統生成器模型有幾個特性:
學習資料成本高:需大量圖文配對資料。
運算成本高:深度網路架構龐大,需大量 GPU 訓練。
黑盒問題嚴重:控制力與可解釋性較差。
MIT 的架構則換了一種邏輯。它將圖像壓縮為少量 token,這些 token 其實就像是抽象的「圖像指紋」,只要調整這些指紋,就能讓圖像變化。
舉例來說:一張紅熊貓的圖可被壓縮為 32 個 token。透過 CLIP 的語意比對指引,我們可以一步步把這些 token 的數值「微調」,直到還原出來的圖越來越像「老虎」。這就像是在 Photoshop 裡面微調參數,只是這次調的是超抽象的 token,而不是像素。
03|三種應用場景展示:換物種、補畫面、修風格
研究團隊展示了幾個明確的應用範例:
跨物種圖像轉換:將一隻紅熊貓逐步轉換為老虎,甚至保留相同姿勢、背景、構圖,僅物種改變。
圖像 inpainting(遮蔽區域補全):將圖片中某區域遮蔽,再使用 token 優化補齊細節,生成合理畫面。
風格變換與語意調整:不改變主體結構,改變風格、顏色或物件種類,例如將狗變貓、將素描轉為實拍。
這三個案例顯示了 MIT 架構的強大彈性——不只是新創圖像,也可以對既有圖像進行局部編輯與控制性修改。
04|這樣的架構有什麼產業價值?
這項研究的關鍵,不只是技術上的可行,而在於它對未來產業架構的潛在顛覆性。可從以下幾點來看:
1. 成本顛覆:
省去大型生成器的訓練與部署,中小企業或獨立開發者也能建構影像 AI 工具。
2. 開發流程簡化:
開發者可專注於設計 tokenizer 與語意控制流程,而不需設計完整生成網路架構。
3. 模型民主化:
大型生成模型主導市場的格局可能改變,小型但可控的架構更利於普及。
4. API 商業模式機會:
未來若 tokenizer 模型開源或模組化,將催生各式「token 優化型圖像 API」,可能取代部分 Stable Diffusion API 的應用場景。
05|延伸解讀:這是一種「語意可操作影像系統」
傳統生成式模型將 prompt 轉為圖像,是種黑盒過程;MIT 的設計則讓你操作圖像背後的「語意 token」,本質上更像是語意可操作的影像系統。
這代表什麼?
你可以微調圖像特定區塊的 token 來局部修改圖像
你可以以「目標語意」作為 guiding signal,不是單一文字 prompt,而是連續優化
你甚至可以透過這樣的機制做「影片轉換」,未來應用於連續影格的 token 優化
這個設計的潛力不僅是「簡化」,而是讓使用者或開發者具備更細膩的圖像控制權。
06|與現有主流架構比較:Stable Diffusion、DALL·E、Gemini
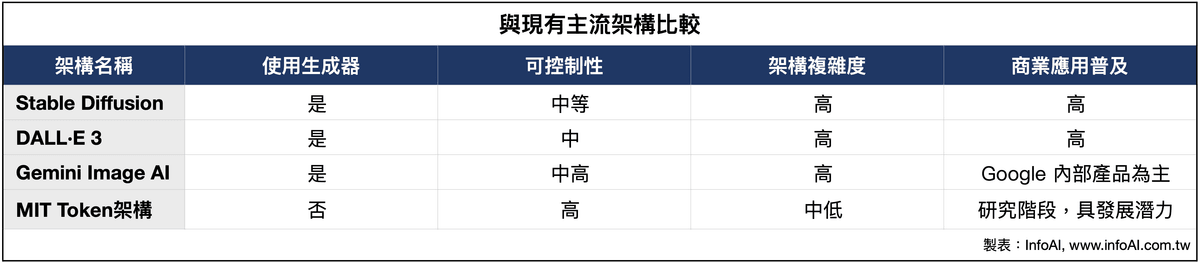
這也說明了,MIT 的設計雖尚不成熟,但其核心思路與發展方向,可能成為主流架構的「輕量替代者」。
07|台灣場景應用想像:設計產業、廣告科技、AI 圖庫平台
MIT 的這項研究對台灣影像與創意相關產業具有以下幾項潛在連結:
A. 廣告與內容產業
設計公司可藉由 token 控制機制實現快速視覺變換或修圖,降低素材重製成本。
B. 教育應用與學研場域
高等教育與技職體系可透過開源模型訓練學生理解生成式 AI 架構原理,亦利於教師創建客製化學習圖像。
C. AI 圖庫與電商圖像處理
圖庫平台可實作類似「token 優化修圖 API」協助用戶自訂素材,電商也能一鍵改變商品風格、色系。
08|延伸思考:影像真實性與倫理風險也將同步升高
當圖像修改變得低成本、高控制,與之而來的是「影像真實性」再度遭到挑戰。相較於需大模型才能產生 Deepfake,token 優化法只要少量資源即可對圖像做精準篡改。這可能加速以下議題爆發:
新聞與政治圖像造假
名人肖像 AI 改圖
原始素材難以溯源
一般人更難辨識 AI 改圖與真實圖片的差異
因此未來若該技術進一步普及,如何建立「影像出處溯源機制」與「AI 圖像信任標章」將是全球共同面對的任務。
09|總結觀察:從模型複雜性走向語意簡化的 AI 新路徑
MIT 的這項研究正顯示出一種新興趨勢:從龐大模型效能競賽,轉向「語意層的簡化與優化」。這樣的路徑更適合資源有限但創意豐富的開發社群與產業中小企業,也為影像 AI 商業化帶來更低門檻的選項。
對於正在考慮 AI 圖像應用的創作者、平台經營者與技術開發者而言,MIT Token 優化法所開啟的技術邊界,不容忽視。
參考資料:
MIT News – A new way to edit or generate images — no generator needed
如果你也對全球最新的AI現況與趨勢有興趣,歡迎點擊[ 按鈕]訂閱InfoAI電子報,或是掃描[QRCode ]/點擊[ 按鈕]加入Line社群,隨時隨地獲得值得閱讀的全球AI新聞精選與解讀。

洞察觀點|GPT-5 從對話工具進化為任務執行者,接下來你會用 AI 幫你完成什麼?
AI 新手必看:GPT、Claude 和 Gemini 模型選擇指南
提升生產力的秘訣,用 GPT 排序你的每日任務
如何用 AI 提升內容創作效率,讓你脫穎而出
OpenAI 推出 ChatGPT 多功能智慧代理:AI 開始幫你「做事」的時代來了
OpenAI AI瀏覽器計畫,挑戰Google Chrome的野心
你未來的工作方式,可能會被這場變革徹底改寫:OpenAI 正準備讓 ChatGPT 變成下一代的 Google Docs + Slack
Mattel × OpenAI:當 Barbie 有了 AI 大腦,你的玩具櫃迎來世代交
OpenAI推ChatGPT超級助理 挑戰Siri與Google Assistant
OpenAI推出語音影片互動功能 ChatGPT進化為AI助理
OpenAI升級Operator代理人,開啟AI進軍企業自動化新時代
OpenAI推ChatGPT-4o語音AI助理 挑戰Siri引爆智慧助理競賽
OpenAI 推出 ChatGPT PDF 匯出功能 強化企業應用場景與專業使用體驗
讓 ChatGPT 更懂你,OpenAI 記憶功能使用指南

AI素養的起點,是擁有世界的視野。
InfoAI為您打開一扇窗,每日博覽全球AI動態,將最新的資訊與洞見盡收眼底。
我們不只讓您『知道』,更讓您『看懂』,從廣博的見識中,淬鍊出屬於您的獨到眼光。
InfoAI 為您:
01|精選出最值得關注的新聞
02|解讀新聞洞察趨勢與啟發
03|從市場商機進行深度探索

提案成功研究院
助力創業成功,募資成功,提案成功。

Content Power
{ AI 世代的出版商 }
運用AI與知識庫
聰明創作好內容